Making personalised Word Clouds2023-01-26
My friends and I joined Discord in 2016, mostly to play and discuss games with text and voice chats.
4 years later, in 2020, I was messing around with Discord Bots and Natural Language Processing when a simple idea occured to me:
what if we had a Discord bot that would read our messages and make a word cloud for each of my friends on the server?
If you're unfamiliar with word clouds, here's an example around Star Wars:
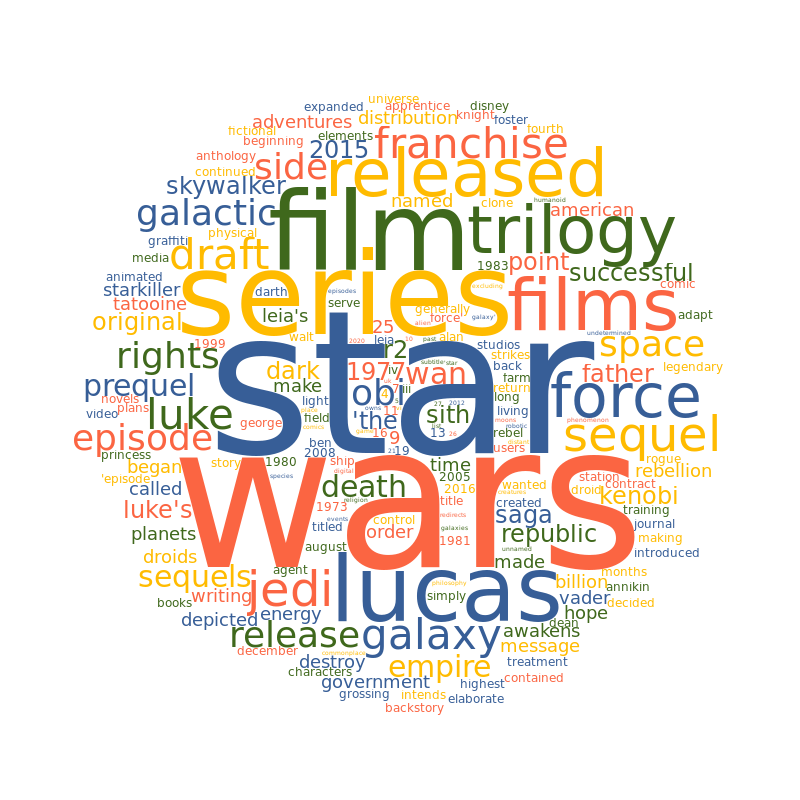
Basically it's a colorful image made up of words that are bigger the more related they are to the subject.
Since we had been typing out messages on a daily basis for 4 years, I figured there was more than enough data to gather words that are typical of each of my friends, and to make Word Clouds out of it.
The main question was: how do we mathematically figure out which words are "typical" of someone ?
In other words, we want a scoring function Sp(w) that take a word w as parameter and outputs a score that represent how much the word is specific to the person p in the server.
The naive approach
When solving new problems, it's always good to try the simplest approach first, it might just work!
Vocabulary
In our case, the simplest approach would be to first compute what I call "the vocabulary", Vp. Intuitively, the vocabulary is the set of words a person tends to use.
Suppose we're making the word cloud of Alice, a biology student. Since Alice occupy much of her time with biology, she will probably tend to use technical biology words more often, such as "endemic", "genotype" etc.
Mathematically, we compute her vocabulary by counting every word Alice wrote on the Discord server, and how much she used them; so Vp(w) = the amount of time Alice used the word w
Note: this doesn't take into account multi-words expressions, such as "Hang in there", which lose all meaning when treated as separate words. We could get around it by counting every pair of words or every triplet of words - these would be called 2-grams and 3-grams - but this is outside the scope of this article so we'll stick with 1-grams here :)
Scoring
Then the scoring would just be Sp(w) = Vp(w), so the words used in the word cloud would just be Alice's most used words. Sounds good right?
... well not exactly.
Implementing this, we run into a problem: the words that are the most used by Alice - and anyone else - are boring uninformative words such as "the", "an", "is", "to", etc. Not at all the technical biology words that we wanted to see!
In the processing of natural language, this problem isn't new. A common solution is to make what's called a "stop word" list, containing all these uninformative words that we don't want to see, and simply filtering them out of our word clouds. Implementing this work decently well in practice, and in our case it does produce a good result!
But there are a few downside I'm not fond of:
- This require an exhaustive stop word list for every language that you want to support. Not easy to find!
- Irrelevant words are not always stop words: In a Discord server dedicated to Pokemon fans, the word "Pokemon" is bound to appear at the top of every vocabulary. It's not a stop word, but we wouldn't want to include it in everyone's word clouds, because in this context, it's not typical of any user!
What we need is a generalization of stop words, a way to quantify how informative a word is in a given context.
Going more general
As we just pointed out, counting how much Alice uses each word is not enough, we also need to filter out words that are common to everyone. So let's try adding the following rule to the scoring function (that decides which word go into the word cloud):
The more a word is used by everyone in the Discord server, the less it is specific to Alice and therefore the less we want it to go into the word cloud.
To implement this, we need to compute one more vocabulary: the global vocabulary, Vg(w), that tells us how much each word as been used in total. It is also the sum of the vocabularies of every member of the Discord server, so it is quite easy to compute. Then we want to penalize words based on how common they are. There are multiples formula we can choose to do that using Vg(w) but the simplest is: Sp(w) = Vp(w)/Vg(w), so to score a word w for a person p we divide how much p used w by how much it was used in total.
Note: Normalizing both vocabularies (diving by the sum) gets us values between 0 and 1, which is much nicer to work with if we want to tweak the formula using powers. For example we could want to penalize common words even more by doing
Sp(w) = Vp(w)/Vg(w)^2, Vg squared will stay in [0;1] instead of blowing up.
And this works! The common words are penalized so the word cloud is no longer filled with "the", "an", "is", "and", and contains words that are actually specific to Alice!
Here's a real output of the bot for a friend on my Discord server (in french):

In this Word Cloud (that also contains emojis) we can see:
- Words related to "l'agregation" (basically a diploma for teacher of High school and above) that this friend was getting: "concours", "l'agreg", "prof", "classe" etc.
- Words with unique spelling typical to this friend: "oskour", "chuila", "doni", "alé"
- Words/emojis that are favored by this friend: "lol", "chats", "désolée", "mortel", "btw"
- Not many french stop words such as "un", "du", "à", "je", "il" etc.
I've skipped over many details of tokenization, dealing with Discord's API, and making the word cloud image itself; but the bottom line is: this scoring does work pretty well!
Optimization note
This solution works fine, and it only requires store 1 vocabulary per person, which is like 10 kB for active users.
10 kB/user would give 10 GB for 1 million users, which is very reasonable, even in RAM. However, I still decided to try and optimize it for fun, because it's an interesting problem to work on :p
But since the score function requires the vocabulary of the user, how could you possibly make it work without storing all of it ?
Well, as it turns out, you don't need the whole vocabulary. Indeed, inspecting user vocabularies reveal that most words are only used once or twice; and since the scoring function multiplies by word count, words that are used very few time are very unlikely to make it into the word cloud.
Instead of storing the whole vocabulary, we can make it work with just the top ~200 words of each user.
But this is where it gets tricky.
If you try the simple solution of making a counter structure that caps at 200 words (Solution A), you run into a problem: the structure will only hold the first 200 unique words it encounters, after which all new words will be ignored.
Alternatively, you could try to estimate the vocabulary by storing the last 200 words used (Solution B) but it has the same issue of ignoring a lot of frequent words that came before. So we need a structure that is able to estimate decently well the most used words, without keeping track of all of them.
If you're familiar with this problem you might have already guessed where this is going: Cache structures. Solution B actually corresponds to the Least Recently Used (LRU) scheme, it's not appropriate here but there is other structures that seem interesting, notably: the Aging version of the Not Frequently Used (NFU) cache family.
Basically, the Aging cache proposes a simple modification of Solution A:
- make a counter that is limited to 200 words
- Each time a word is read:
2.1.a. If it's not in the counter and there's still room for it we add it to the counter with a count of k
2.1.b. If it's already in the counter we add k to it
2.2 every other word in the counter are decreased by a fixed amount a (or divided). If a word reaches 0 it is free to be replaced.
The crucial step here is 2.2, it is where the "aging" takes place. Words in the counter decay over time, allowing new words to take their place if they are not refreshed often enough! The speed of aging is controlled with parameter a, while k control the lifespan of new words.
Of course this biases the estimated vocabulary towards recent words, but this is perfectly fine for my use, because I wish for the vocabularies to evolve over time as new expressions come into users vocabulary.